About Us
UNC Biomedical Image Analysis Group
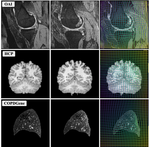
The Biomedical Image Analysis Group at the University of North Carolina at Chapel Hill (UNC-biag) focuses on the design of computational algorithms to extract quantitative measures from biomedical data. While our emphasis is on image data (e.g., obtained via magnetic resonance imaging, computed tomography, or microscopy) our analyses also include clinical measures and genomics. The group is led by Marc Niethammer.
Our work is highly interdisciplinary and includes collaborators from a wide range of disciplines such as statistics, applied mathematics, radiology, surgery, and epidemiology. Consequently, we also publish in venues ranging from clinical journals, to medical conferences (such as MICCAI and IPMI) to computer vision conferences (such as CVPR and ECCV), to machine learning conferences (such as NeurIPS, ICML, and AAAI).